Systematic Service Decomposition with Context Mapper and Service Cutter
Context Mapper provides a generator that decomposes your domain model into Bounded Contexts in a systematic manner. The service decomposition tool is based on Service Cutter. Based on a catalog of 16 coupling criteria and a graph clustering algorithm, the generator suggests how an application could be decomposed into Bounded Contexts, services, or components.
Note that it is not our goal to automate the job of domain modelers and software architects! The generated decompositions are just suggestions and can give you hints how your domain objects are coupled. Don’t expect that the perfect decomposition is generated for you without questioning it.
This tutorial illustrates how you can use Service Cutter inside Context Mapper, or export your domain model for Service Cutter out of a CML file.
The Domain Model
We use the DDD sample application (Cargo Tracking) for this tutorial. As a first step, we modeled the domain of the application in CML. You can find the model here.
We modeled the domain inside one single Bounded Context. The context contains four Aggregates with its Entities and Value Objects:
BoundedContext CargoTracking {
Aggregate Cargo {
owner CargoPlaner
Entity Cargo {
aggregateRoot
- TrackingId trackingId
- Location origin
- RouteSpecification routeSpecification
- Itinerary itinerary
- Delivery delivery
}
/* shortened Aggregate here */
}
Aggregate Location {
owner Administrators
Entity Location {
aggregateRoot
- UnLocode unLocode
String name
}
/* shortened Aggregate here */
}
Aggregate Handling {
owner CargoTracker
DomainEvent HandlingEvent {
- HandlingEventType handlingEventType
- Voyage voyage
- Location location
Date completionTime
Date registrationTime
- Cargo cargo
}
/* shortened Aggregate here */
}
Aggregate Voyage {
owner VoyageManager
Entity Voyage {
aggregateRoot
- VoyageNumber voyageNumber
- Schedule schedule
}
/* shortened Aggregate here */
}
}
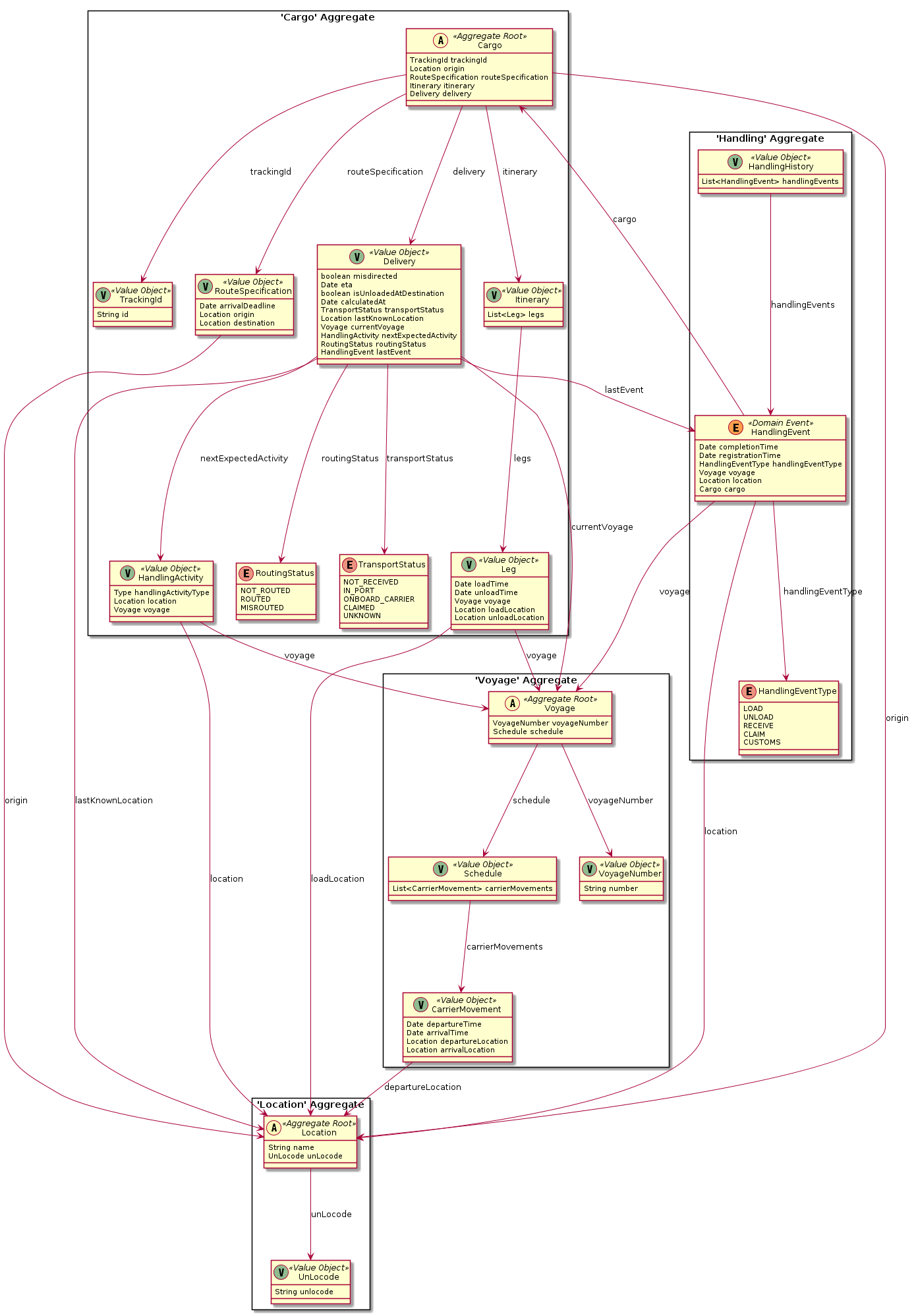
The CML code above just gives you an impression how the model looks like but is shortened a lot. Find the complete model here. The following PlantUML diagram (generated with Context Mapper) illustrates the domain model graphically:
Use Case Modeling
With a Bounded Context definition as the one above you are already able to generate new service decompositions or Service Cutter files. However, we highly recommend to model your use cases as well, since they have a big impact on the ideal service decomposition.
On the User Requirements page of our language reference you can find out how use cases or user stories are modeled in CML. For this tutorial based on the DDD sample application we modeled the use cases provided by the Service Cutter sample files:
UseCase ViewTracking {
interactions
read "Cargo" with its "trackindId",
read "HandlingEvent" with its "handlingEventType", "location", "completionTime",
read "Delivery" with its "transportStatus", "estimatedArrivalTime", "misdirected",
read "Voyage" with its "voyageNumber",
read "RouteSpecification" with its "destination"
}
UseCase ViewCargos {
interactions
read "Cargo" with its "trackingId",
read "RouteSpecification" with its "destination", "arrivalDeadline",
read "Delivery" with its "routingStatus"
}
UseCase BookCargo {
interactions
read "Location" with its "unLocode",
update "Cargo" with its "trackingId",
update "RouteSpecification" with its "origin", "arrivalDeadline", "destination"
}
UseCase ChangeCargoDestination {
interactions
read "Cargo" with its "trackingId",
read "RouteSpecification" with its "destination",
update "RouteSpecification" with its "destination"
}
/* we shortened this listing to save space (find all use cases in the original CML file) */
Note that we only modeled the Entities with its read and written attributes (nanoentities) here. The CML syntax allows you to add more details to use cases and/or user stories, but the information above are absolutely necessary for Context Mapper to use the cases/stories as user representations in Service Cutter.
The CML use cases or user stories will be mapped to the Service Cutter’s Use Case definition.
Define Owners (Teams)
A Bounded Contexts is not necessarily a system or component. A team can constitute a Bounded Context as well. If you decompose a system you should respect existing teams (code and domain model owners) as well, since they have an influence to the coupling. In CML you can assign owners on the level of Aggregates.
This might not make sense for the DDD sample application, as the domain model is not that big. However, we assigned the Aggregates to four different teams to illustrate how this is done:
BoundedContext CargoTracking {
Aggregate Cargo {
owner CargoPlaner
/* removed content here to save space */
}
Aggregate Location {
owner Administrators
/* removed content here to save space */
}
Aggregate Handling {
owner CargoTracker
/* removed content here to save space */
}
Aggregate Voyage {
owner VoyageManager
/* removed content here to save space */
}
}
/* team definitions: */
BoundedContext CargoPlaner { type TEAM }
BoundedContext CargoTracker { type TEAM }
BoundedContext VoyageManager { type TEAM }
BoundedContext Administrators { type TEAM }
The CML team assignments will be mapped to the Service Cutter’s Shared Owner Group definition.
Other User Representations
In our example we just used Use Cases and Shared Owner Groups. However, Service Cutter supports many other user representations that can help to improve the suggested service decompositions:
- Entity Relationship Model (ERM)
- Use Cases
- Shared Owner Groups
- Aggregates
- Entities
- Predefined Services
- Separated Security Zones
- Security Access Groups
- Compatibilities
Note: CML offers language features to cover all those user representations. That means: Context Mapper derives all Service Cutter user representations automatically for you, as long as you use the corresponding CML language feature. The following list summarizes how you can use all those language features (and links to the corresponding pages of the language reference):
- Use Cases: The use cases for Service Cutter are derived from the CML use cases and/or user stories (already shown above). You can find examples how to model them here. Also have a look at Olaf Zimmermann’s blogpost for an enhanced example.
- Note: You have to specify your use cases with entities and their attributes, otherwise we cannot use them as user representations in Service Cutter.
- Shared Owner Groups: Shared owner groups are derived automatically, if you assign owners to your Aggregates (define which development teams own which parts of the system/code) as done above.
- Aggregates: Aggregates are first-class citizens in CML. Thus, the Aggregates for Service Cutter are simply derived by the CML Aggregates.
- Entities: Entities are first-class citizens in CML. Thus, the Entities for Service Cutter are simply derived by the CML Entities, Value Objects, and Domain Events (see tactic DDD).
- Predefined Services: Predefined services are derived by the Bounded Contexts you already provide before calling the service cut generator. This means: each Bounded Context you already identified is mapped to a predefined service.
- Separated Security Zones: The CML language allows you to assign each Aggregate to a security zone. Thereby you can indicate that parts of your Bounded Contexts must be realized in separated security zones.
- Security Access Groups: The CML language allows you to assign each Aggregate to a security access group. Thereby you can indicate that parts of your Bounded Contexts have different security access requirements.
- Compatibilities: All compatibilities (
contentVolatility,structuralVolatility,availabilityCriticality,consistencyCriticality,storageSimilarity, andsecurityCriticality) can be modeled on Aggregate level in CML.
The Service Cutter Configuration DSL (SCL)
We originally developed the Service Cutter Configuration DSL (SCL) to ease the modeling of Service Cutter’s user representations, since Service Cutter requires the data in JSON and this is cumbersome to write manually. To generate service decomposition suggestions in Context Mapper it is no longer required to modify it manually. It creates and updates itself automatically.
You only have to open and/or edit the file in one case: if you want to export the JSON files and analyze your system in the original Service Cutter tool. In case you generate service cut’s in Context Mapper, it does not make sense to modify the file manually, as it is always overwritten with the data we derive from the CML model.
Now, having a CML and a SCL model, you have two options how you can proceed:
- Generate new service cut’s in Context Mapper
- Analyze your model in Service Cutter
Generate Service Cut’s
You can create new CML files with new service decompositions by calling “Propose New Service Cut”:
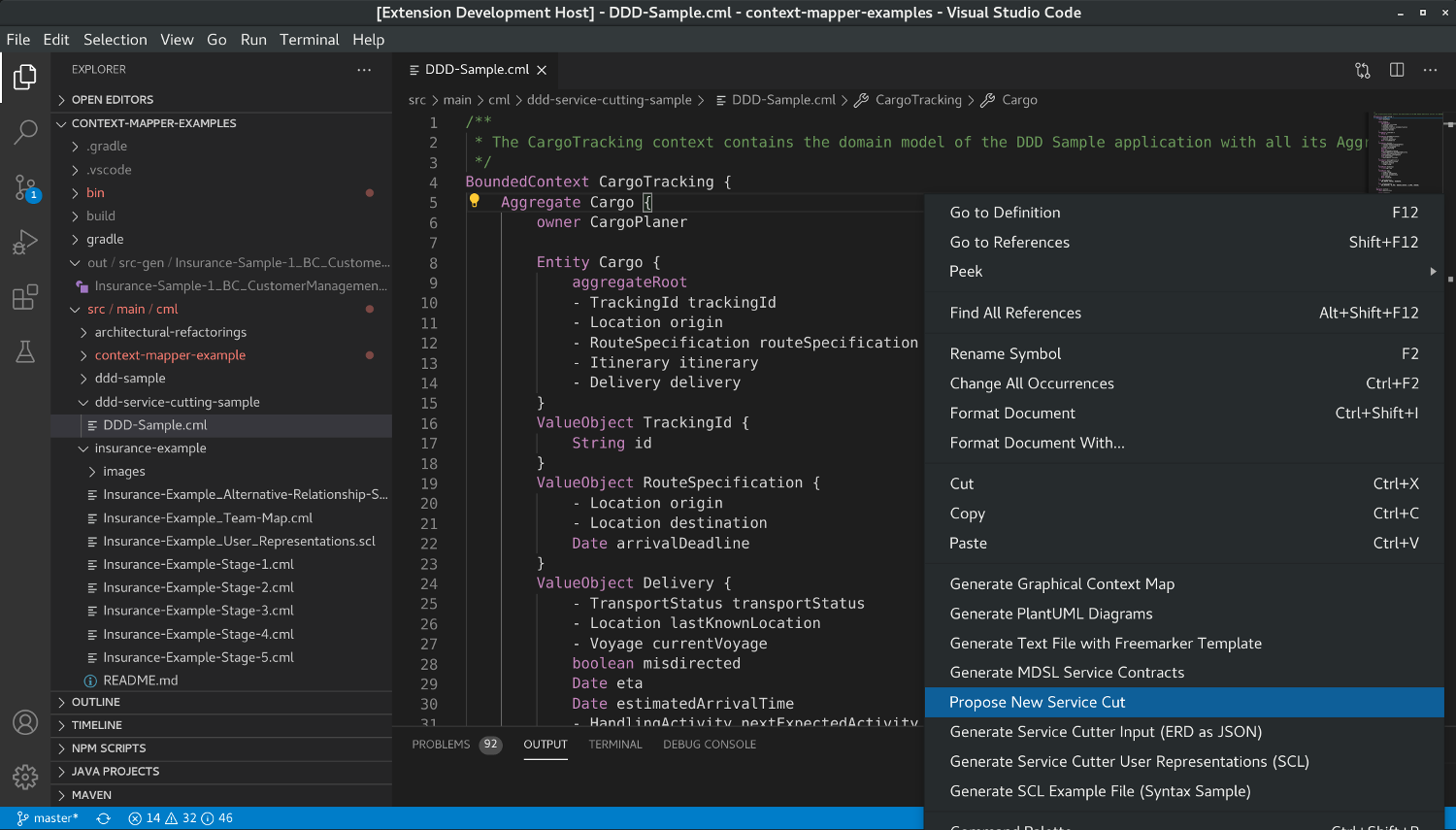
Note that depending on the graph clustering algorithm (we explain how you can change the algorithm below) you may get a different result each time you call the generator. In this case, you can generate multiple suggestions by calling the generator multiple times; it always create a new *.cml file containing a new service decomposition for your model:
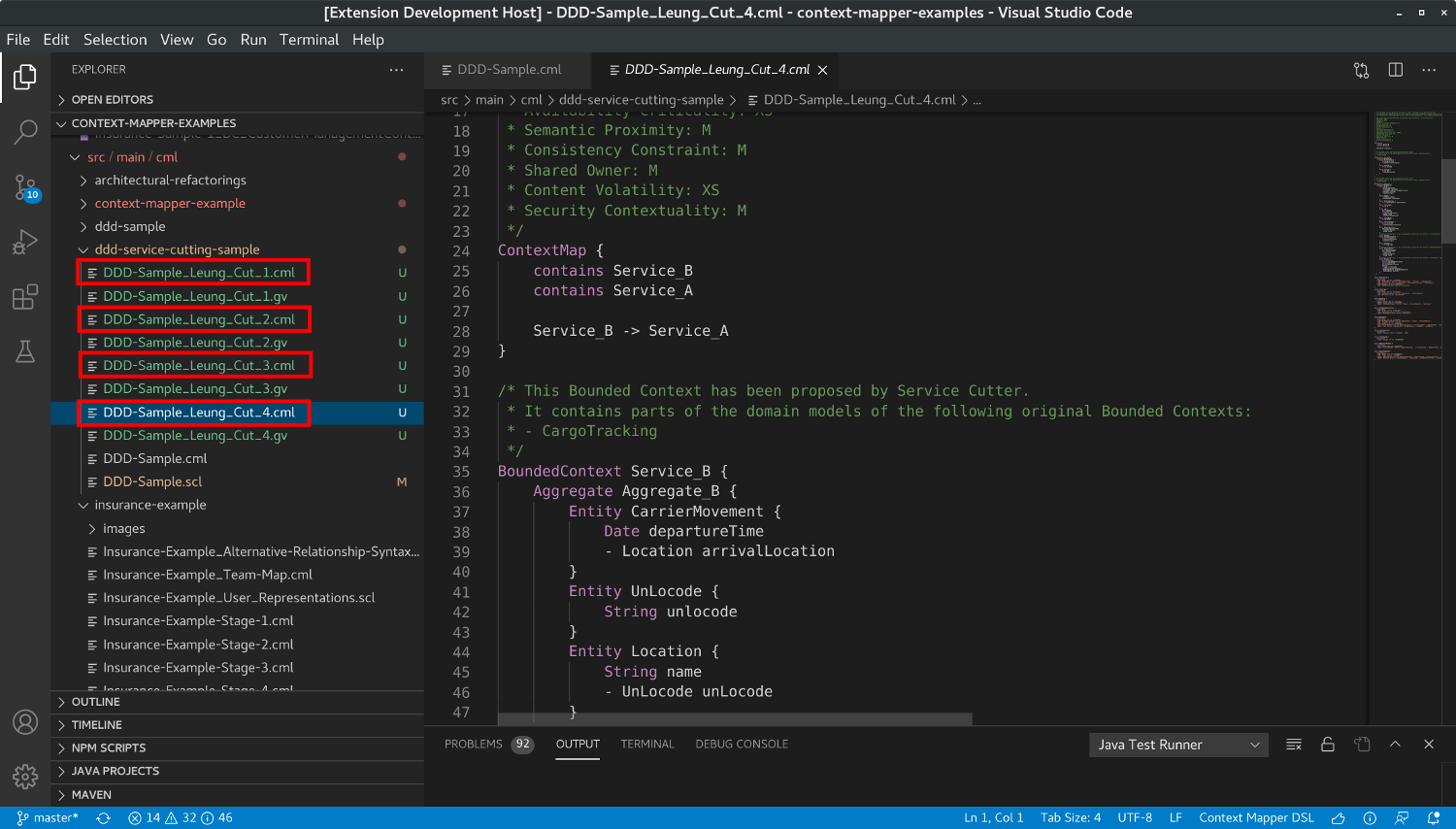
As you can see above, the generator additionally creates a *.gv file each time:

You don’t necessarily need this file, but it can be useful for traceability and while trying to understand how Service Cutter works. It contains the graph Service Cutter uses for the clustering as Graphviz DOT file. Thereby you can for example change the scoring in the .servicecutter.yml file and analyze which impact this has on the actual graph behind the scenes. Besides the graph with the weighted egdes, each line/edge contains a comment that explains the calculated weight on the basis of the used coupling criteria.
If your model is not too big you can use online tools such as http://webgraphviz.com/ or http://graphviz.it/ to illustrate the graph graphically:
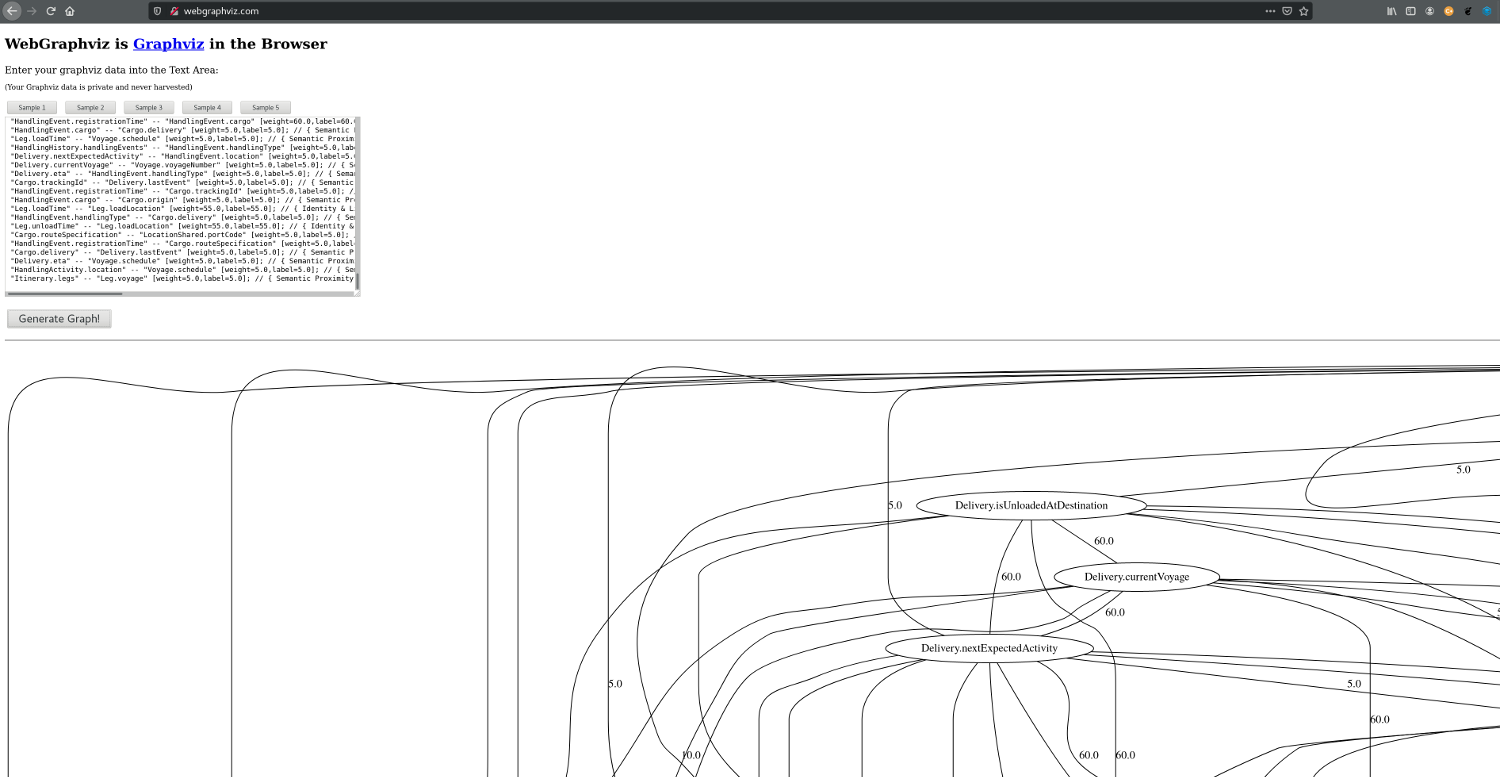
However, the graph generated with our example above is already too big for those tools (they do not respond when pasting the DOT graph into their editors). In such a case you can generate a graphic locally on the command line (in case you have Graphviz installed):
dot -Tpng DDD-Sample_Markov_Clustering_Cut_4.gv -o DDD-Sample_Markov_Clustering_Cut_4.png
This can also take a while but you have the generated file after a some seconds.
Nevertheless, as you can see in the following image, visualizing the graph is really only usefull for small examples. The graph produced by our DDD sample model is simply too big:

However, the file can still be useful to compare different results with different criteria scorings. In addition, one could use the file and process it using tool-support in the future. Other (research) projects could also use the output to analyze Service Cutter’s behavior.
Criteria Scoring
Service Cutter allows you to score the individual coupling criteria. Thereby you can define which criteria are more important than others in your specific case. In case you use Service Cutter, you can control the scores on the user interface (see screenshot below). In case you use the service cut generator in Context Mapper, you have to change the scores in the .servicecutter.yml file. The file is automatically generated into the root folder of your project when you call the service cut generator for the first time:

You can change the scoring in the priorities part of the YAML file (see screenshot above). The following values are allowed: IGNORE, XS, S, M, L, XL, and XXL.
Note: In case you work with Eclipse you have to ensure that the .* resources filter is disabled in the project/file explorer (so that you can see the .servicecutter.yml file):

Note: As you can see in the following screenshot, we always dump the current configuration as a comment into the generate service suggestions:
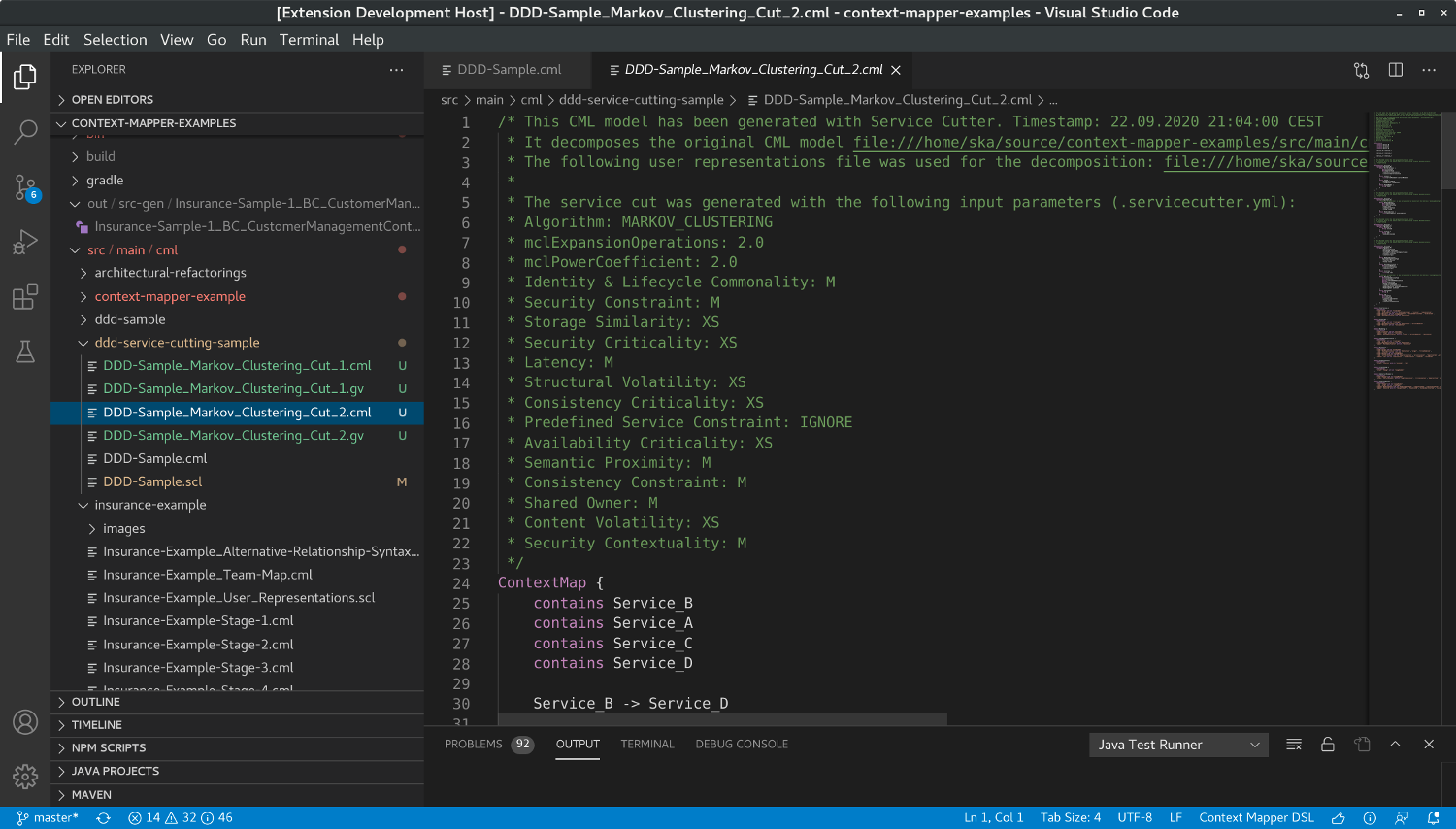
This can be very helpful regarding traceability and understandability when analyzing the generated service cut’s.
Algorithms
You can further change the clustering algorithm in the .servicecutter.yml file. We currently support the following three algorithms:
- Markov Clustering (MCL):
MARKOV_CLUSTERING(default) - Epidemic Label Propagation (Leung):
LEUNG(non-deterministic) - Chinese Whispers:
CHINESE_WHISPERS(randomized, and therefore non-deterministic)
More information on the .servicecutter.yml configuration file can be found here.
Extract a Suggested Service in the Original Model
The generated *.cml files with the service cut suggestions typically do not contain all the information you modeled into your original CML model. These files are not meant to continue to work with. We just use them as a suggestion on how a system could be decomposed and then (maybe) refactor the original model accordingly.
In case a suggested cut contains a service which you find a suitable Bounded Context, you can extract such a service in the original model with a refactoring we provide.
With our example above we generated a cut that contained the following service (Service_C):
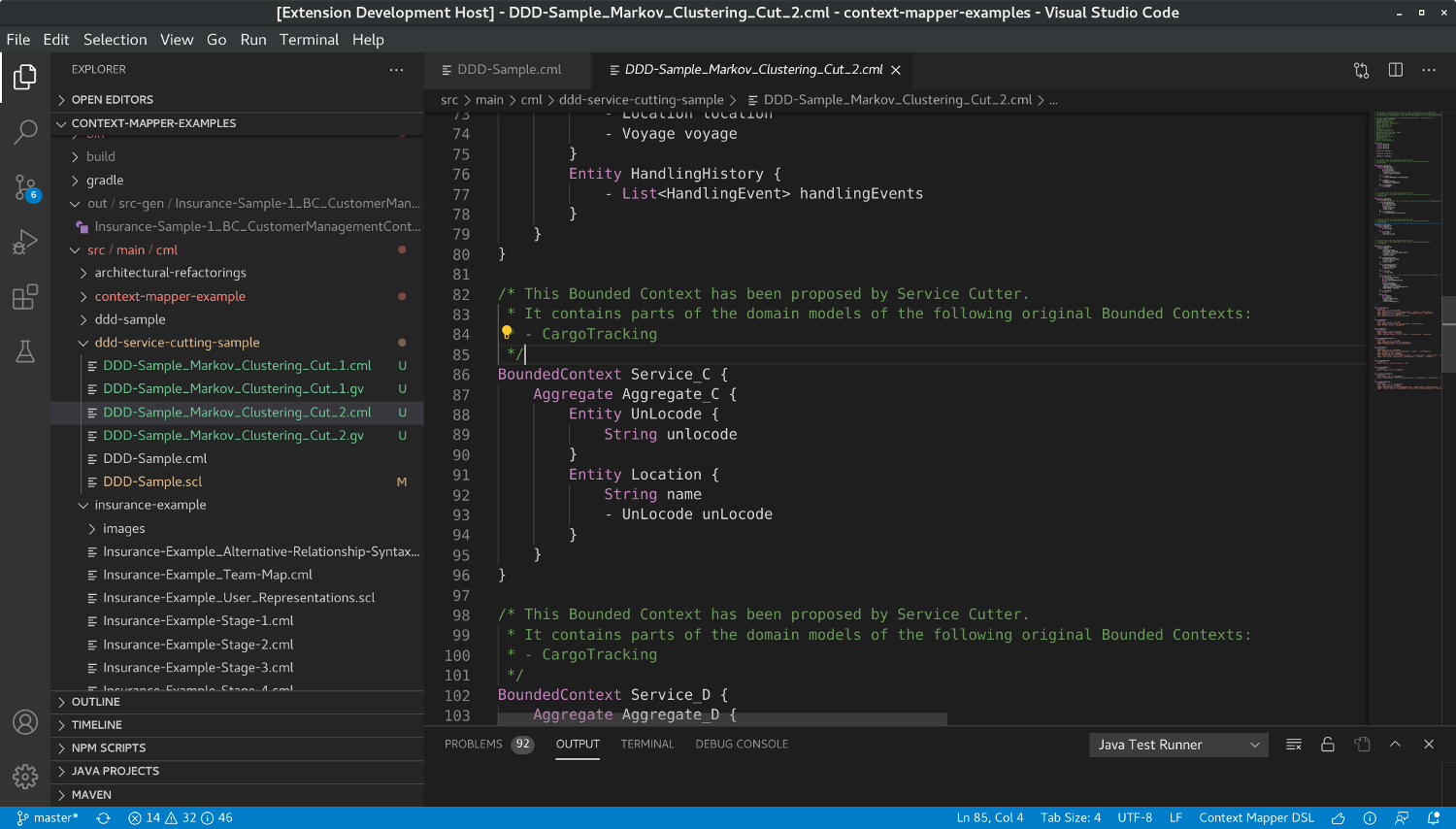
The service contains everything related to the Location entity. Providing all the locations and their management as a separate service (Bounded Context) could be a reasonable design decision.
Given such a service in a generated cutting suggestions, you can now apply the Extract Suggested Service in Original Model refactoring:
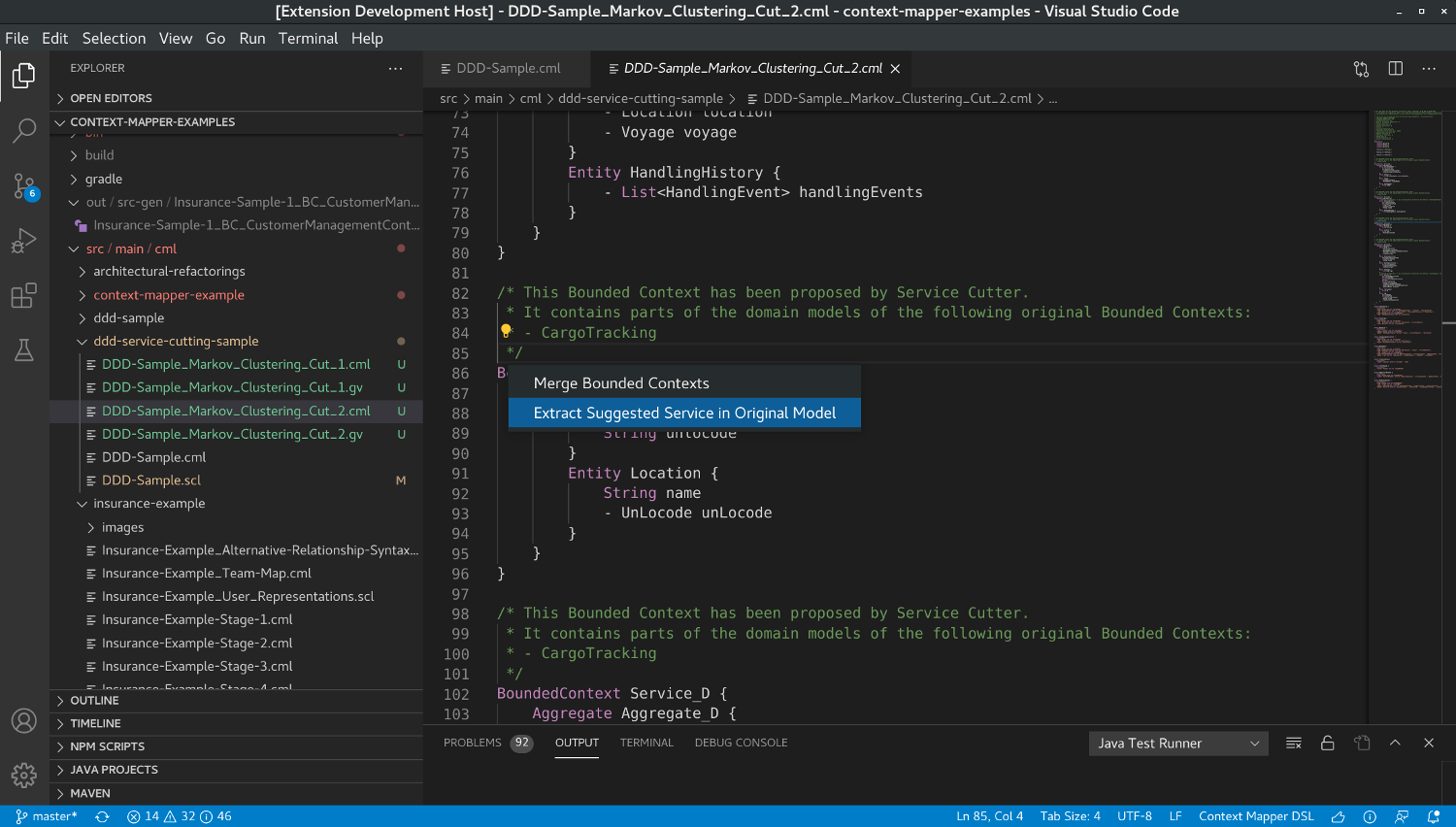
As you may remember, our original model (at the beginning of this tutorial) only contained one single Bounded Context. This refactoring supports you in extracting the suggested service above from this exising (monolithic) context.
Note: For this refactoring to work properly, you are not allowed to rename the CML files. The refactoring has to locate the original model, which can only be done if they are still named according our given pattern.
The refactoring will ask you to provide a name for the selected Bounded Context first. We chose the name LocationContext for the suggested service. Context Mapper will open the original model with the applied change: (in VS Code in a split view and the changes can be saved or reverted; in Eclipse in a normal editor and the changes are already persisted)
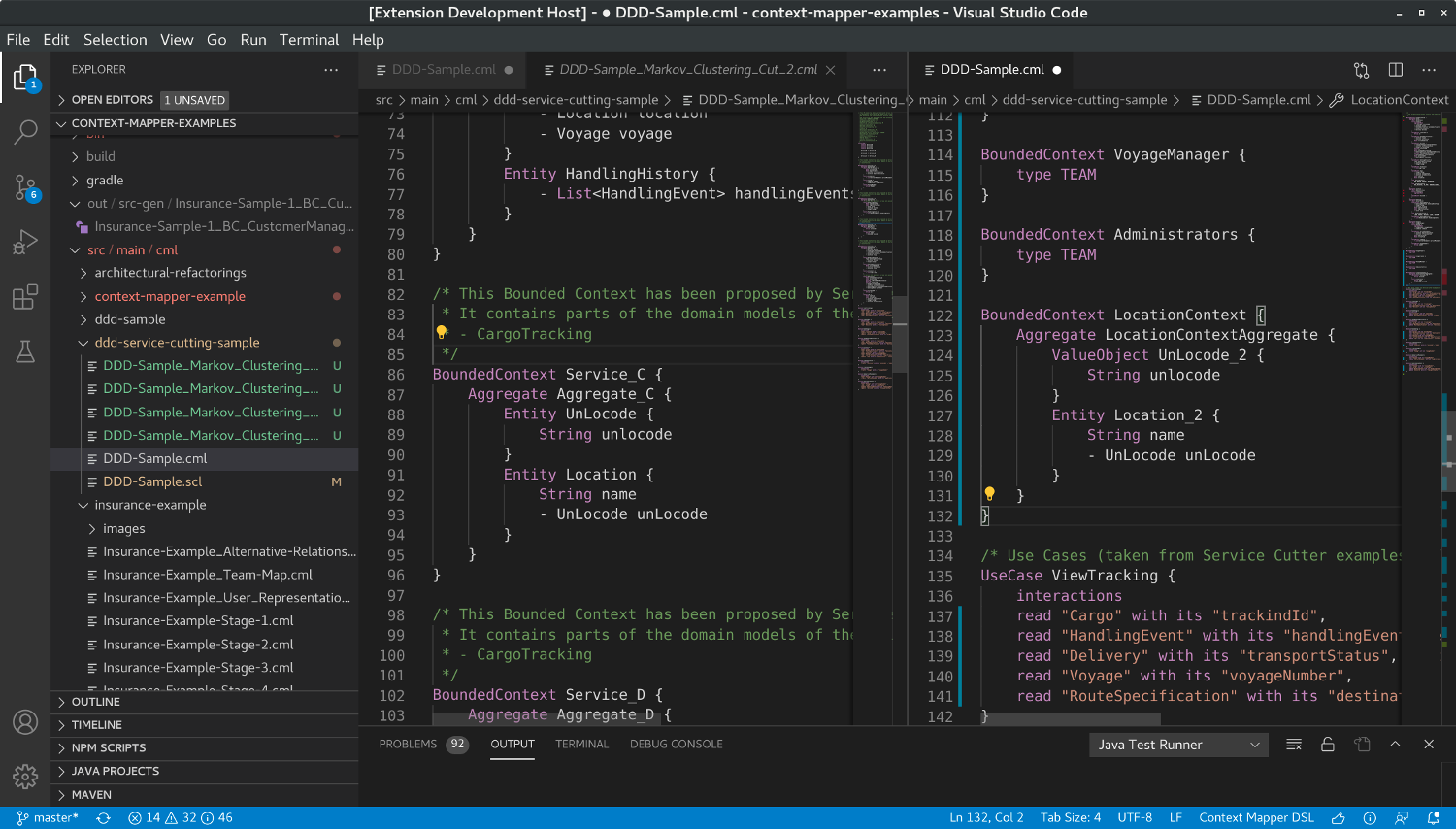
As you can see in the original model in the right view above, a new LocationContext got extracted. However, the refactoring implementation is quite straight forward and typically requires you to do some manual cleanup work. For example: it currently does not delete the original entities (in this case Location and UnLocode) since they could still contain some nanoentities (potentially). Therefore we generate unique names (in this case Location_2 and UnLocode_2), which might not be the desired names. If the original entities are no longer needed, you can delete those and rename the entities of your new Bounded Context with the rename refactoring in VS Code or Eclipse.
Thats it. This is how the current tooling in Context Mapper supports you in proposing service cut’s and extract potential services in your original CML model. In the following we have a look at how you can use your CML model to generate the input files required by the Service Cutter tool.
Analyze Model in Service Cutter
Instead of generating new service cuts in Context Mapper, it is also possible to analyze the decompositions in Service Cutter. While Context Mapper generates new CML models, Service Cutter illustrates the graph clusterings graphically.
To use Service Cutter you need the ERM and user representations as JSON files. Both can now easily be generated with Context Mapper. The ERM is generated out of the CML file…
… and the user representations out of the SCL file:
Note: In case you haven’t generated service cut’s before, you don’t have a SCL file already. No worries: you can simply generate it from your CML file by calling Generate Service Cutter User Representations (SCL) in the context menu of the CML editor. Don’t confuse this with the Generate SCL Example File (Syntax Sample) entry, which only generates an exemplary SCL file (this can be used in case you want write your SCL file manually).
Now you can start Service Cutter and import the model to analyze it. You can start Service Cutter easily by cloning the repository and using Docker:
git clone git@github.com:ServiceCutter/ServiceCutter.git
cd ServiceCutter
docker-compose up
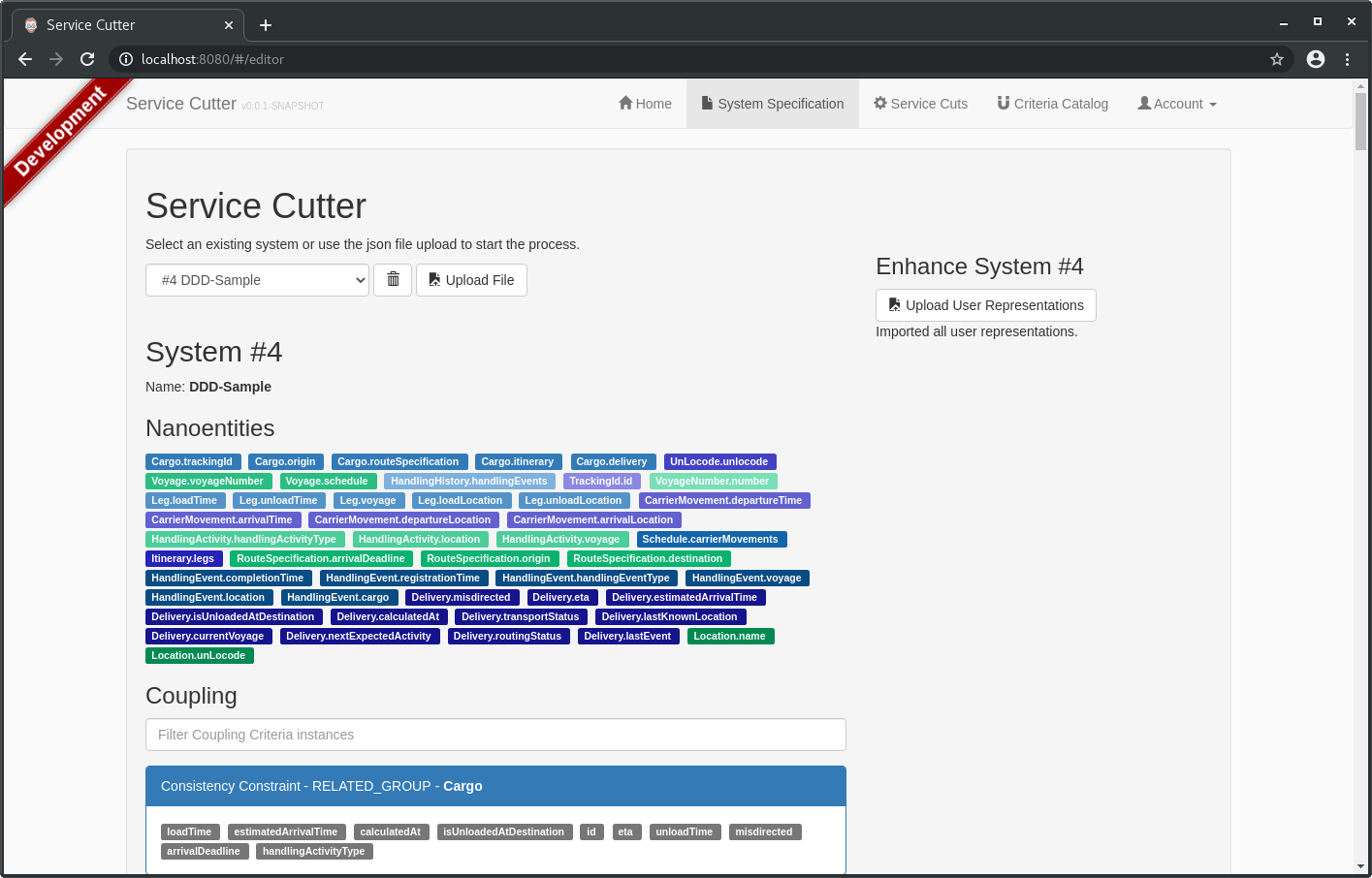
Once the application is up-and-running you can open it in your browser under http://localhost:8080 (user: admin, password: admin). Under the System Specification tab you can upload the ERD file first, and then add the user representations:
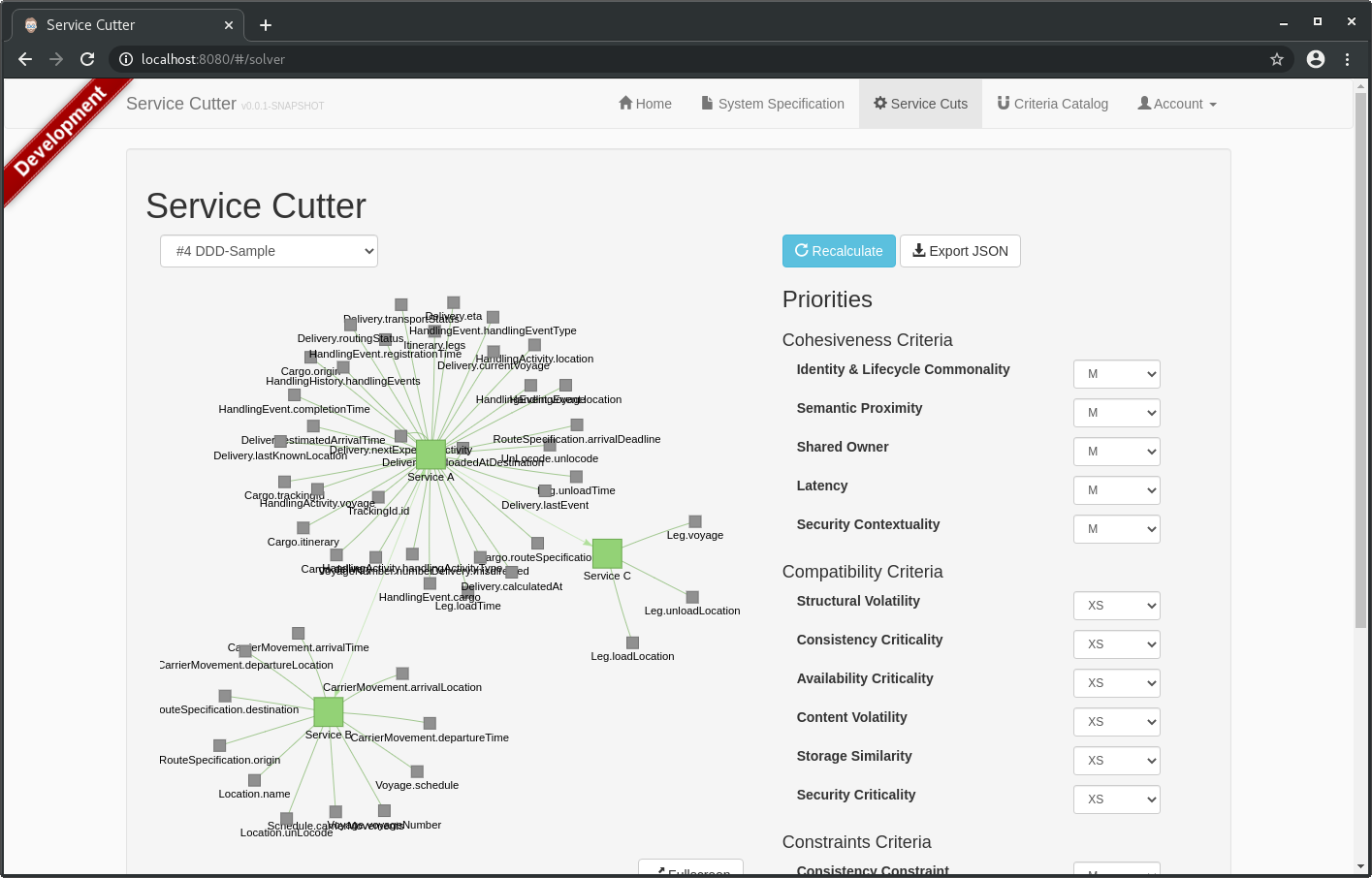
After you have imported the two files you can switch to the Service Cuts tab and analyze different decompositions depending on the criteria scoring:
Summary
In this tutorial we have shown how you can use Service Cutter to generate decomposition suggestions for your system modeled in CML. It is important to note that we only understand them as suggestions. They can help to analyze the coupling between objects in your domain model and therefore may help you in finding the right service decomposition and Bounded Contexts. Don’t expect that the produced result is the best decomposition without questioning them seriously!
For our DDD sample application we used the generated outputs to discover some parts of the domain model which seem to be loosely coupled from the rest. Concretely, we extracted a Bounded Context for the Location Aggregate and one for the Voyage Aggregate. You can find this CML model here.
To extract new Bounded Contexts according to the ideas you have developed by using Service Cutter you may also use our Architectural Refactorings. For example, you can extract Aggregates by using AR-5: Extract Aggregates by Cohesion.
In order to present and discuss decomposition suggestions with your colleagues, you can use our generators to create graphical representations (graphical Context Map or PlantUML diagrams) of the service decompositions.