Context Map Suggestions with Service Cutter
The Service Cutter tool proposes a structured way to service decomposition. It suggests how a system could be decomposed into services according to 14 prioritized coupling criteria. Domain model elements are required as input. The tool then applies graph clustering algorithms to identify possible service cuts, which are returned as output. The approach was proposed in this paper.
Context Mapper Integration
We provide a Service Cutter library, which is a fork of the original Service Cutter, to be able to offer its structured decomposition approach in Context Mapper. The library allows you to propose new decomposition suggestions in the form of CML Context Maps. The decompositions are derived from the original coupling criteria catalog.
Once you have modeled your system in CML or discovered it from existing code, you can generate new decomposition suggestions or service cuts by using the following context menu entry:
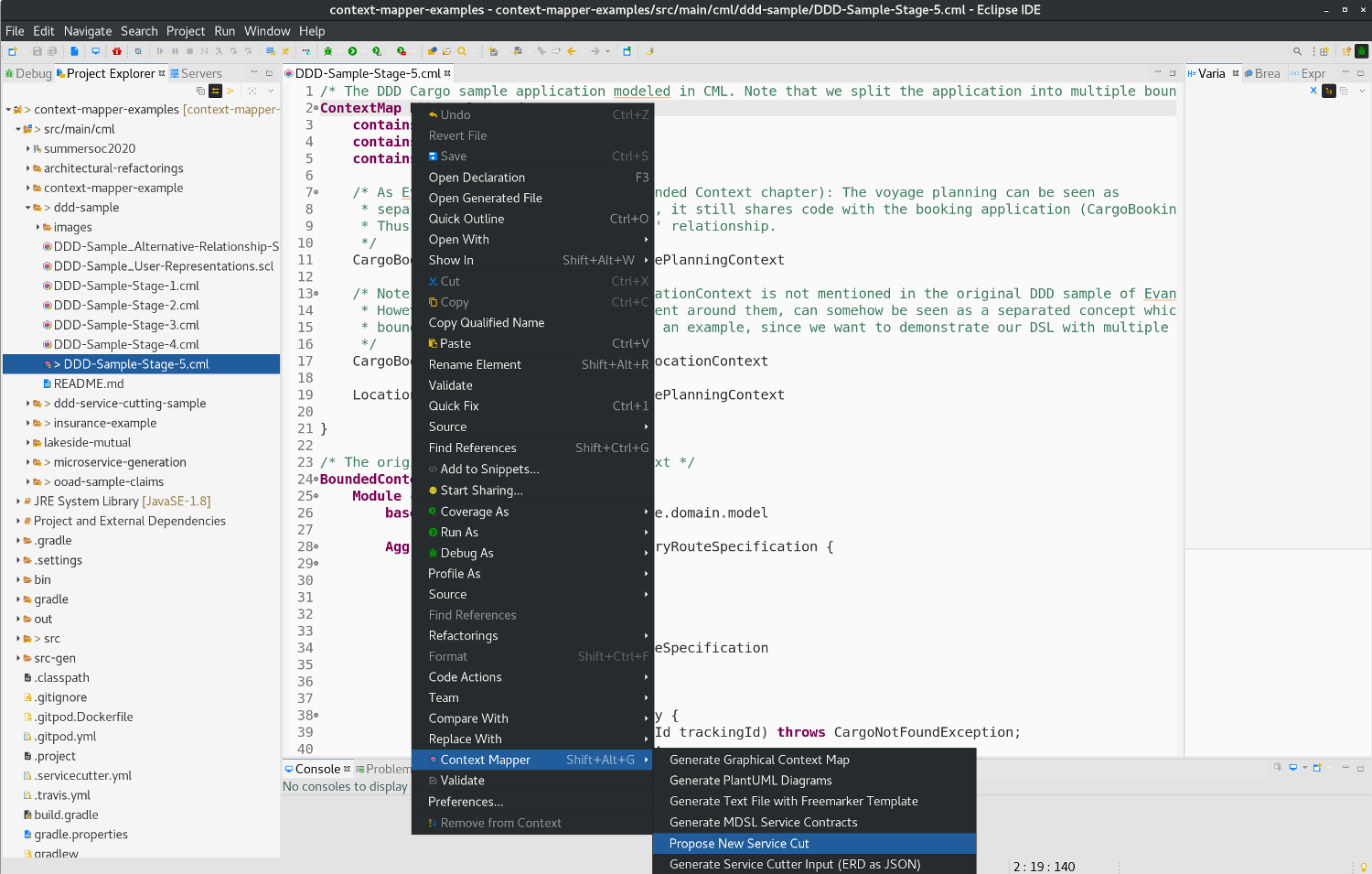
Input and Preconditions
Service Cutter needs the system to be described in entities and so-called nanoentities. This structure is automatically derived from your CML model. The following preconditions have to be fulfilled so that we are able to derive the basic structure of your system required by Service Cutter (ERD part):
- Your CML model must include Bounded Contexts with entities and attributes.
- Without attributes, we cannot derive nanoentities and Service Cutter cannot calculate decompositions.
User Representations
In addition to the basic structures (including Bounded Contexts, Aggregates, domain objects, and attributes), Service Cutter takes so-called user representations which improve the suggested service cuts immensely. The CML language offers corresponding features so that Context Mapper can derive all the user representations automatically. Of course, we can only derive individual user representations if you use the corresponding CML features. The following list shows how the representations are derived and which CML features you have to use:
- Use Cases: The use cases for Service Cutter are derived from the CML use cases and/or user stories. You can find examples how to model them here. Also have a look at Olaf Zimmermann’s blogpost for an enhanced example.
- Note: You have to specify your use cases with entities and their attributes, otherwise we cannot use them as user representations in Service Cutter.
- Shared Owner Groups: Shared owner groups are derived automatically, if you assign owners to your Aggregates (define which development teams own which parts of the system/code).
- Aggregates: Aggregates are first-class citizens in CML. Thus, the Aggregates for Service Cutter are simply derived by the CML Aggregates.
- Entities: Entities are first-class citizens in CML. Thus, the Entities for Service Cutter are simply derived by the CML Entities, Value Objects, and Domain Events (see tactic DDD).
- Predefined Services: Predefined services are derived by the Bounded Contexts you already provide before calling the service cut generator. This means: each Bounded Context you already identified is mapped to a predefined service.
- Separated Security Zones: The CML language allows you to assign each Aggregate to a security zone. Thereby you can indicate that parts of your Bounded Contexts must be realized in separated security zones.
- Security Access Groups: The CML language allows you to assign each Aggregate to a security access group. Thereby you can indicate that parts of your Bounded Contexts have different security access requirements.
- Compatibilities: All compatibilities (
contentVolatility,structuralVolatility,availabilityCriticality,consistencyCriticality,storageSimilarity, andsecurityCriticality) can be modeled on Aggregate level in CML.
Solver Configuration
Once you generated your first service cut you will find a .servicecutter.yml file in the root directory of your project: (if you work with Eclipse you have to disable the .* resources filter to see the file in the project/file/package explorer)
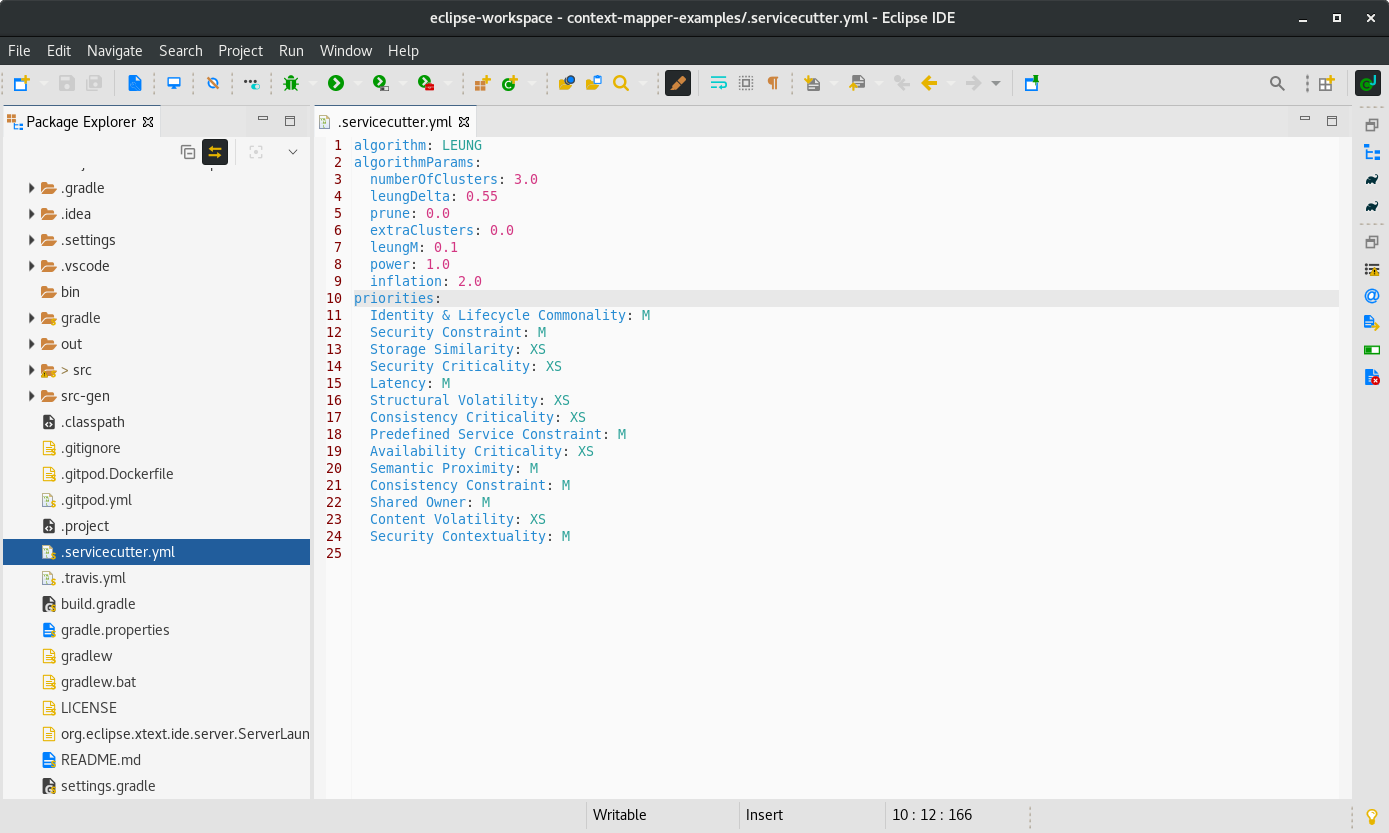
In this file you can customize the priority of each coupling criterion, as you can in Service Cutter. You can further change the clustering algorithms. Details about the config file can be found here.
Example Result
When calling Propose New Service Cut, Context Mapper will create a new CML file with a new decomposition suggestion. This is one example decomposition generated for the DDD cargo sample application:
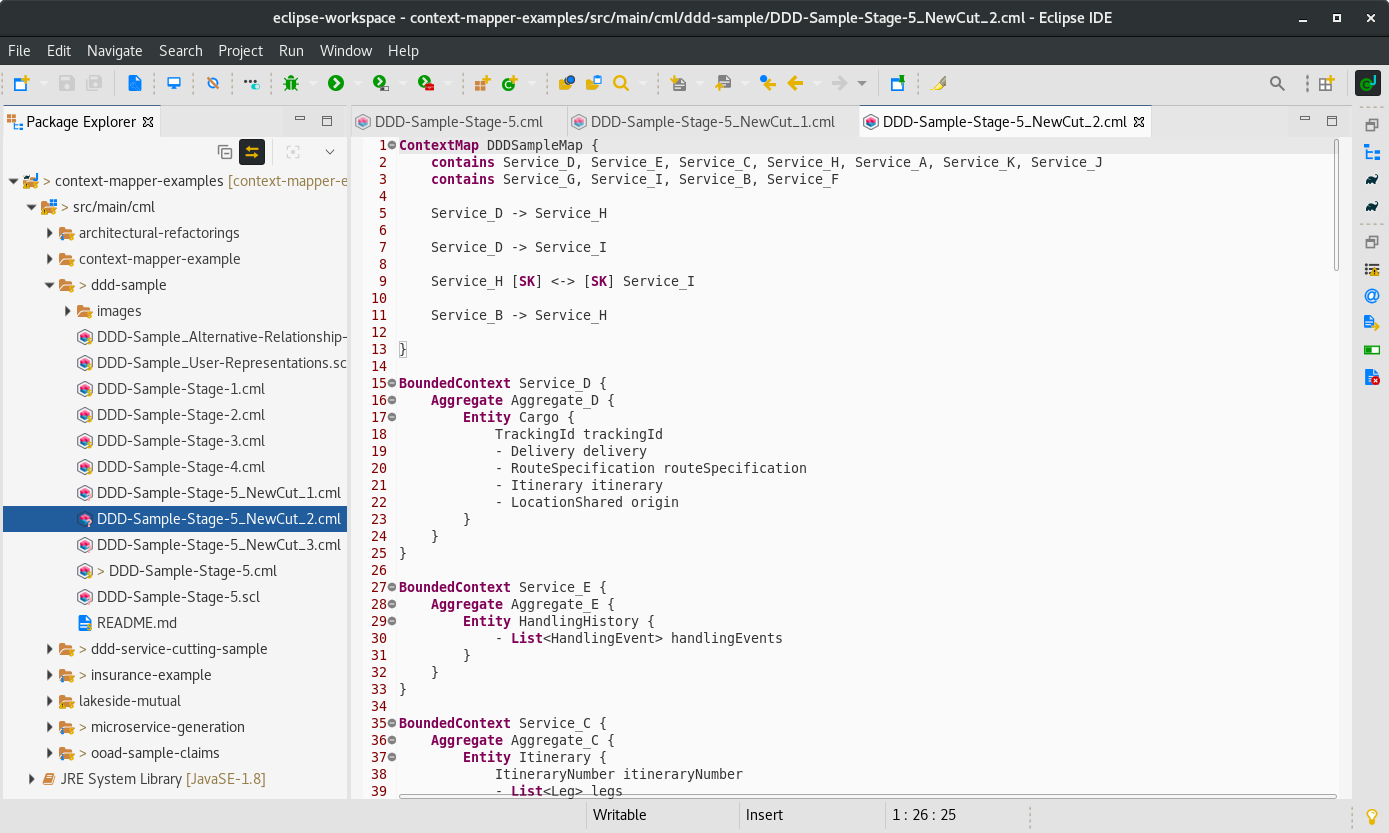
Besides decomposition suggestion itself, Context Mapper will generate a Graphviz DOT file (*.gv) that represents the graph that was used by Service Cutter (for the graph clustering).
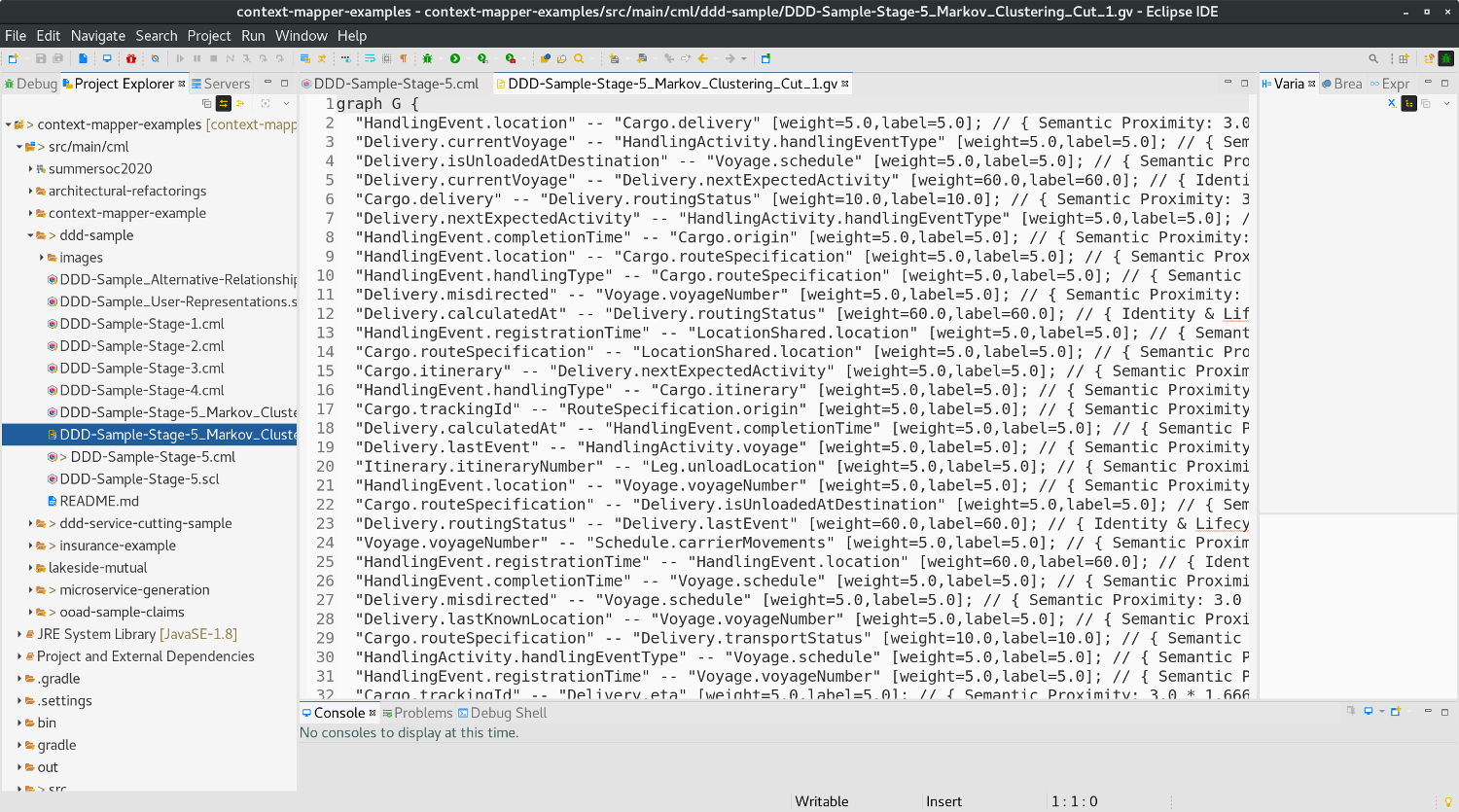
This file can help to understand and retrace the result produced by Service Cutter. Each edge of the graph has a comment that explains the weight value that has been calculated on the basis of the coupling criteria.
You can further use online tools such as http://webgraphviz.com/ and http://graphviz.it to illustrate the graph graphically: (just copy the file content into their editors)
Note: The graph that Service Cutter uses gets huge very quick. In our experience these online visualization tools can often not generate the visual graphs due to their complexity and size.
Service Cutter Input File Generators
If you want to work with the original Service Cutter tool, a JHipster application, you can also use our Service Cutter generators to derive the needed input files in the JSON format from your Context Map. Simply save them as JSON files (in Context Mapper) and upload them there (in the original Service Cutter). We also describe this in our service decomposition tutorial.